隨著服務規模的增長,Log 管理面臨許多挑戰。過去,服務通常會將 Log 寫入本地檔案進行保存,但這種做法存在多種缺點,比如:沒有一個集中管理的地方,導致追查 Log 需要東找西找才能找出線索,又或是面對各式各樣的 Log 沒有一套工具來輔助分析,將會變得非常困難。針對上述問題,ELK Stack 或許是不錯的選擇。
ELK Stack 由 Elasticsearch、Logstash 與 Kibana 三個服務組成,這套工具提供了收集、查詢、分析 Log 的功能,甚至可以根據 Log 的內容繪製出圖表,進而提升整體系統的可觀測性,是目前市面上非常熱門的 Log 管理方案。

Elasticsearch 是一套分散式搜尋引擎,提供強大的全文檢索功能。資料會以 Schema-less 的 JSON 格式保存,也就是說不需要事先定義結構即可儲存資料。根據官方的說明,在儲存一筆資料時,Elasticsearch 會在短短一秒內建立 索引(Index),並且可以立即進行搜尋。Elasticsearch 提供 RESTful API 來存取資料,開發者可以使用自己習慣的程式語言來操作它。官方還針對多種程式語言(如 Java、Python、JavaScript 等)實作了 客戶端。
補充:Elasticsearch 強大的社群也有針對其他程式語言實作客戶端,詳細內容可以參考這份文件。
在 Elasticsearch 中,每一筆資料稱為 文件(Document),每個 Document 會由多個 欄位(Field) 組成。Field 是 key-value 組成的資料,這些資料的型別可以自行指定,也可以讓 Elasticsearch 自動推斷。前面提到的 Index 則是由多個 Document 組成的集合。
在 ELK Stack 中,Elasticsearch 扮演著儲存、搜尋 Log 的角色,透過它強大的檢索功能可以快速地將要查詢的 Log 找出來,做更進一步的分析。

Logstash 是一個強大的資料處理管道,能夠收集、過濾並處理來自不同來源的資料,並將處理後的資料傳送至其他系統,以 ELK Stack 來說,會將資料傳送到 Elasticsearch 中。透過 Logstash 可以將 Log 的內容做進一步的處理,比如:將特定文字轉換成特定欄位,這樣的好處是可以將某些重點資訊變成一致的欄位,在查詢上會更加便利。
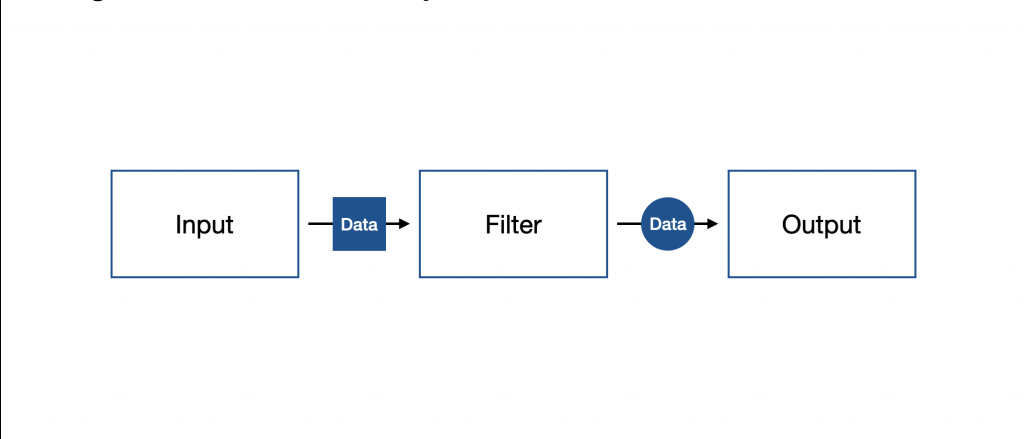
Logstash 的工作流程有三個階段,分別是:輸入(Input)、過濾(Filter) 與 輸出(Output),需要透過撰寫 pipeline.conf 來進行定義。
補充:後面會針對如何套用
pipeline.conf做更詳細的說明。
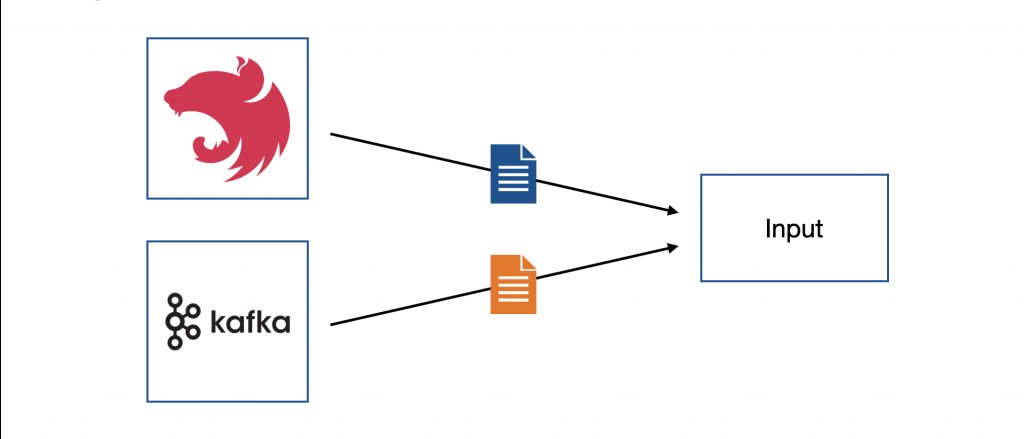
資料來源在系統規模不斷增加的情況下會越來越複雜,因此 Logstash 支援許多種資料來源,如:檔案、HTTP、Kafka、TCP 等。
補充:由於 Logstash 支援的資料來源非常多,不適合在這篇文章中逐一列出,有興趣可以參考官方文件。
下方是範例設定,在 pipeline.conf 定義 input 區塊,在該區塊內定義 syslog 作為資料來源,監聽的 Port 為 5000:
input {
syslog {
port => 5000
}
}
// ...
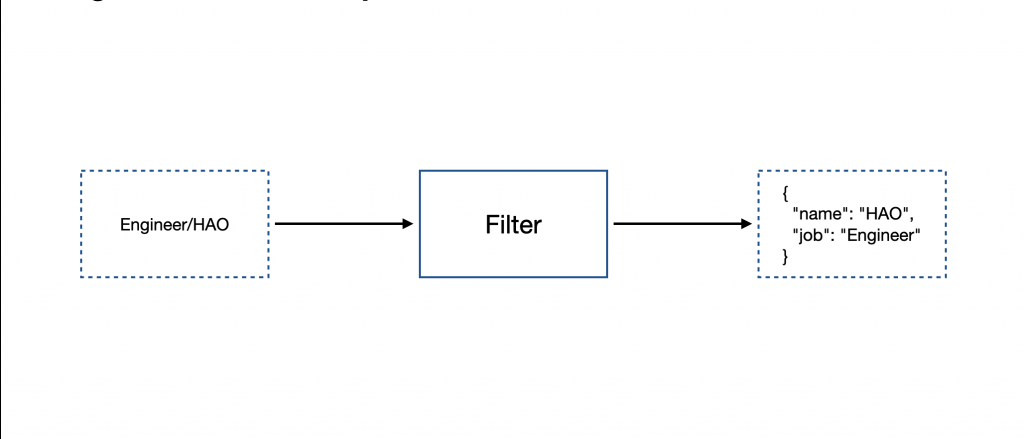
當資料進入 Logstash 後,可以在此階段針對資料進行處理,比如:將時間戳記(Timestamp)轉換成標準日期格式、將欄位名稱進行轉換、將資料型別進行轉換等。
補充:由於 Logstash 支援的 Filter 非常多,不適合在這篇文章逐一介紹,有興趣可以參考官方文件。
下方是範例設定,在 pipeline.conf 定義 filter 區塊,在該區塊內定義 mutate 來對資料進行改寫,使用 rename 將 time 欄位改名為 log_timestamp:
// ...
filter {
mutate {
rename => {
"time" => "log_timestamp"
}
}
}
// ...
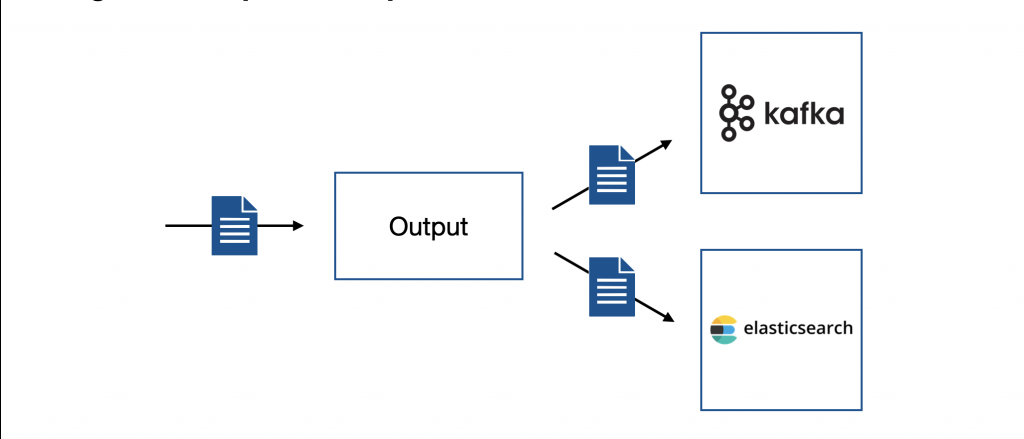
當資料處理完畢後,Logstash 會將資料傳送到特定地點,比如:Elasticsearch、Kafka、檔案等。
補充:由於 Logstash 支援的 Output 非常多,不適合在這篇文章逐一介紹,有興趣可以參考官方文件。
下方是範例設定,在 pipeline.conf 定義 output 區塊,在該區塊內定義 elasticsearch,裡面需填入 hosts 來指定 Elasticsearch 的節點位址,並針對輸出資料進行 Index 的歸類:
// ...
output {
elasticsearch {
hosts => ["https://elasticsearch:9200"]
index => "docker-logs-%{+YYYY.MM.dd}"
}
}

Kibana 是一套將 Elasticsearch 資料視覺化的工具,它提供了圖表、儀表板、分析等功能,讓我們可以針對來自各方的 Log 進行更進一步的分析,從中找出問題或是潛在機會。除此之外,Kibana 還提供了 Kibana 查詢語言(Kibana Query Language, KQL) 讓我們可以透過它來過濾 Elasticsearch 的資料,以我自身的經驗而言,對於定位問題非常有幫助。
補充:針對 KQL 後續會有部分的使用案例,如果對 KQL 想深入了解,可以參考官方文件。
由於 ELK Stack 有 Elasticsearch、Logstash 與 Kibana 要啟動,這邊建議使用 Docker Compose 來幫助我們快速啟動這些元件。建立一個 docker-compose.yml 並添加下方設定:
version: '3.7'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:<IMAGE_TAG>
container_name: <ELASTIC_SEARCH_NAME>
env_file:
- .env
ports:
- 9200:9200
volumes:
- ./esdata:/usr/share/elasticsearch/data # 映射資料夾避免 Container 銷毀時資料遺失
logstash:
image: docker.elastic.co/logstash/logstash:<IMAGE_TAG>
container_name: <LOGSTASH_NAME>
volumes:
- ./logstash/pipeline/pipeline.conf:/usr/share/logstash/pipeline/pipeline.conf # 映射 Pipeline 的設定
- ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml # 映射 Logstash 的設定
ports:
- 5000:5000
- 9600:9600
depends_on:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:<IMAGE_TAG>
container_name: <KIBANA_NAME>
ports:
- 5601:5601
depends_on:
- elasticsearch
上方設定檔可以看到在 elasticsearch 這裡透過 env_file 指定 Elasticsearch 要讀取的環境變數檔,該環境變數檔的內容可以讓我們微調 Elasticsearch 的一些設定。下方是範例設定檔,指定 ELASTIC_PASSWORD 來設定預設使用者 elastic 的密碼,並指定 discovery.type 為 single-node 告訴 Elasticsearch 只有架設單一節點:
ELASTIC_PASSWORD=123456
discovery.type=single-node
Logstash 的部分則有 pipeline.conf 與 logstash.yml 需要設定,首先,針對 logstash.yml 的部分進行設置,將 http.host 設為 0.0.0.0:
http.host: "0.0.0.0"
接著設定 pipeline.yml,這邊可以先定義好資料來源有哪些?要如何進行資料處理?要將處理後的資料傳送到哪裡?針對資料來源的部分,假如是要收集來自 Docker Container 的 Log,那麼可以採用 syslog 的方式進行收集。範例設定如下:
input {
syslog {
port => 5000
}
}
接著要定義如何進行資料處理,假如要接收來自 NestJS 應用程式的 Log,這個 Log 是由 pino 所產生,產生的格式大致上會如下所示:
{
"level": 30,
"time": 1723964154994,
"pid": 42,
"hostname": "6fc64737f491",
"req": {
// ...
},
"res": {
// ...
},
"msg": "request completed"
}
我希望可以在存入 Elasticsearch 之前做一些簡單的資料處理,規則如下:
level 依照 pino log level 把數字轉換成 Level 文字。time 欄位轉換成標準日期,並以 @timestamp 欄位儲存。pid 的資料型別轉換為 integer。message 欄位中,假如解析失敗,該筆 Log 就不會存入 Elasticsearch。根據上述規則,可以運用 json filter 來將輸入的資料進行 JSON 解析並存入 message 欄位,如果解析失敗,會替該筆資料加上 _jsonparsefailure 的 標籤(Tag),當含有此 Tag 時,透過 drop filter 捨棄該筆資料。如果解析成功,透過 mutate filter 將 pid 欄位轉換成 integer 型別,接著,運用判斷的方式將 level 欄位轉換成對應的 Log Level。最後,運用 date filter 將 time 欄位的 Timestamp 轉換成標準日期格式,並存入 @timestamp 欄位中,同時移除 time 欄位:
// input settings
filter {
json {
source => "message"
tag_on_failure => ["_jsonparsefailure"]
}
if "_jsonparsefailure" in [tags] {
drop { }
}
mutate {
convert => {
"pid" => "integer"
}
}
if [level] == 10 {
mutate { update => { "level" => "TRACE" } }
}
if [level] == 20 {
mutate { update => { "level" => "DEBUG" } }
}
if [level] == 30 {
mutate { update => { "level" => "INFO" } }
}
if [level] == 40 {
mutate { update => { "level" => "WARN" } }
}
if [level] == 50 {
mutate { update => { "level" => "ERROR" } }
}
if [level] == 60 {
mutate { update => { "level" => "FATAL" } }
}
date {
match => ["time", "UNIX_MS"]
target => "@timestamp"
remove_field => ["time"]
}
}
最後,要來將轉換後的資料傳送到 Elasticsearch,所以在 output 的地方設置 elasticsearch,需要指定 hosts 與 index,同時將 user、password 一同設定上去:
// Input setting
// Filter setting
output {
elasticsearch {
hosts => ["https://elasticsearch:9200"]
index => "docker-logs-%{+YYYY.MM.dd}"
user => "elastic"
password => "123456"
ssl => true
ssl_certificate_verification => false
}
}
注意:因為我們是在本地端進行測試,可能會遇到 SSL 相關問題,可以將
ssl設為true,並把ssl_certificate_verification設為false來避開,不過在正式環境還是建議把 SSL 相關設定調整好。
以上設定檔都準備好之後,就可以透過下方指令啟動 ELK Stack:
$ docker-compose up -d
使用 Kibana 來檢查各個元件是否有正確運作,透過瀏覽器存取 http://localhost:5601 會看到下方畫面,需要填入 Enrollment Token:
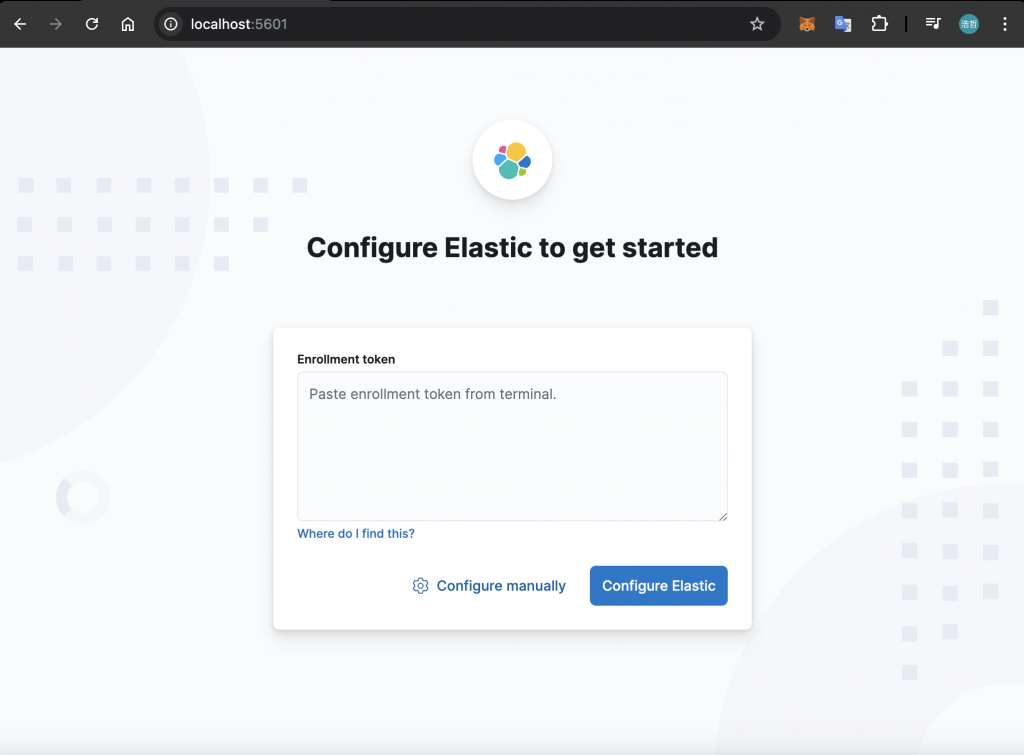
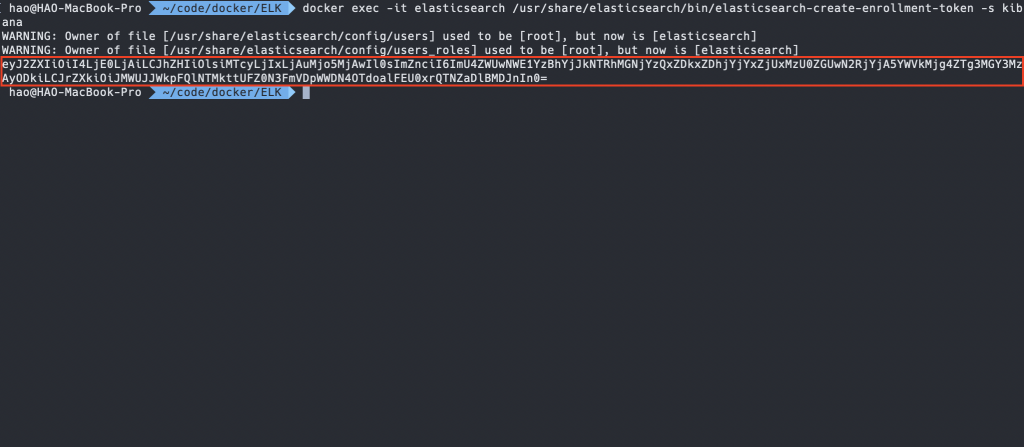
Enrollment Token 可以在 Elasticsearch Container 中產生,下方是產生的指令:
$ docker exec -it <ELASTIC_SEARCH_NAME> /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
產生的 Enrollment Token 會顯示於終端機中,將文字複製下來並貼入 Kibana 的頁面中:
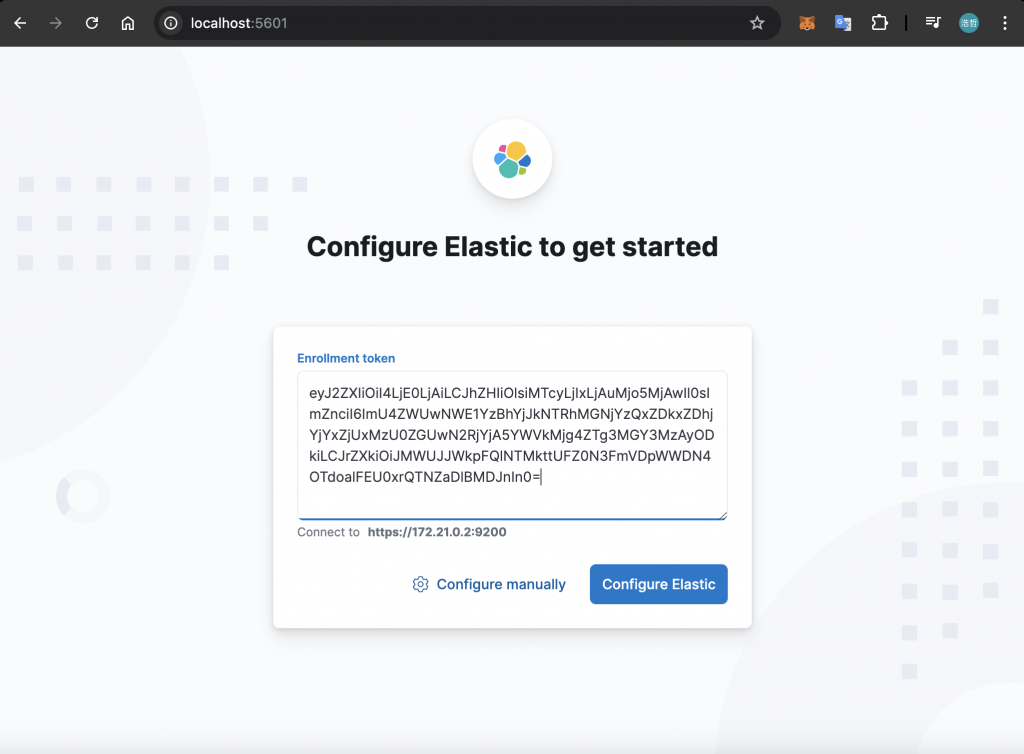
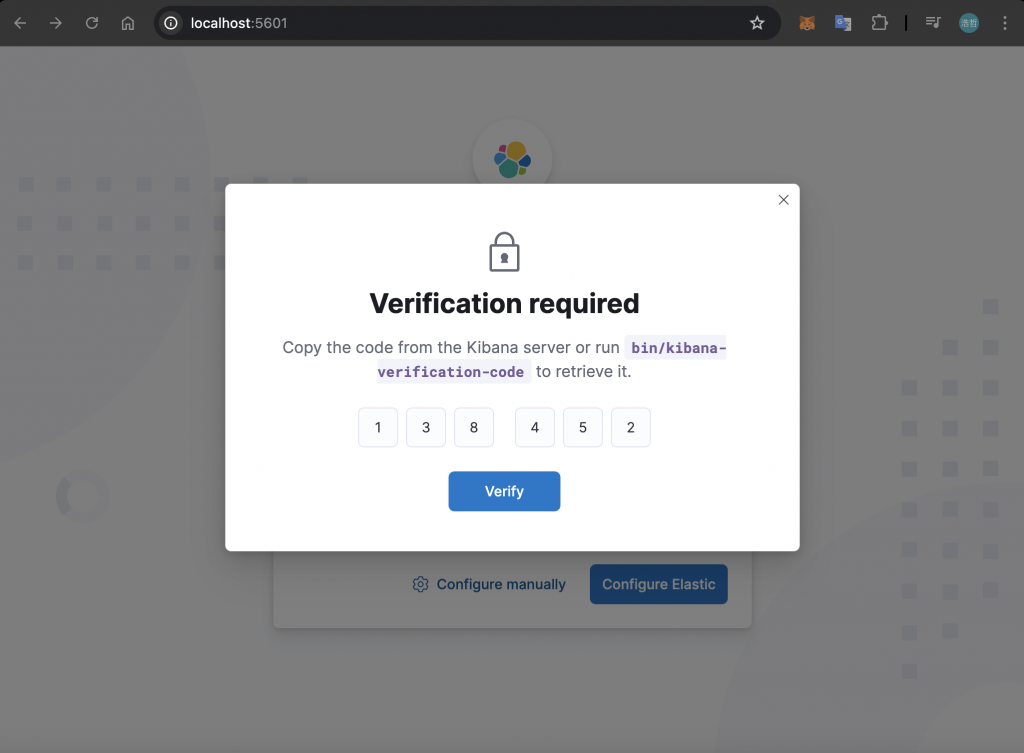
接著,Kibana 會要求輸入驗證碼:
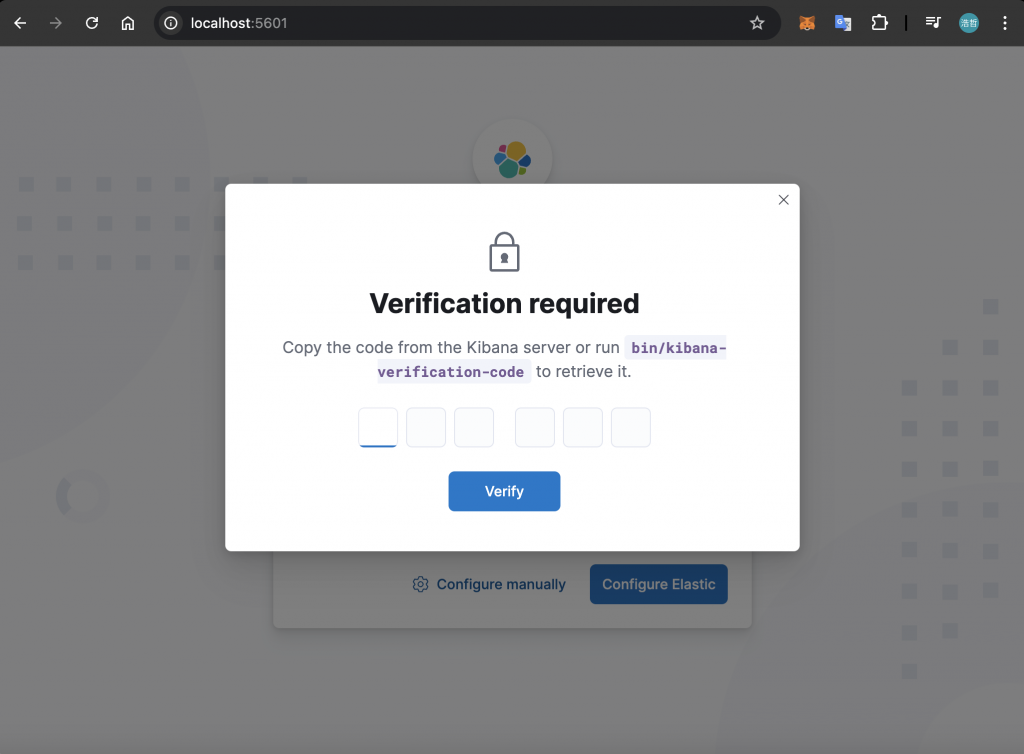
驗證碼可以在 Kibana Container 中產生,下方是產生的指令:
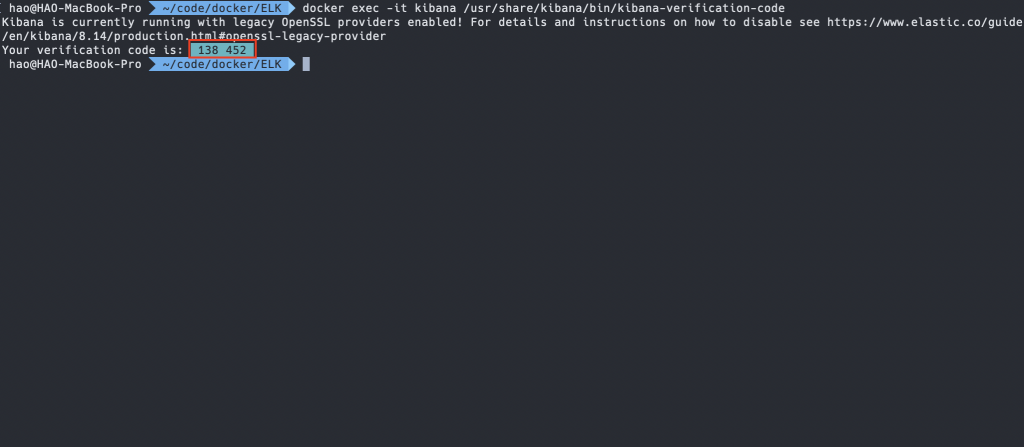
$ docker exec -it <KIBANA_NAME> /usr/share/kibana/bin/kibana-verification-code
產生的驗證碼會顯示於終端機中,將驗證碼輸入至 Kibana 的確認視窗中:
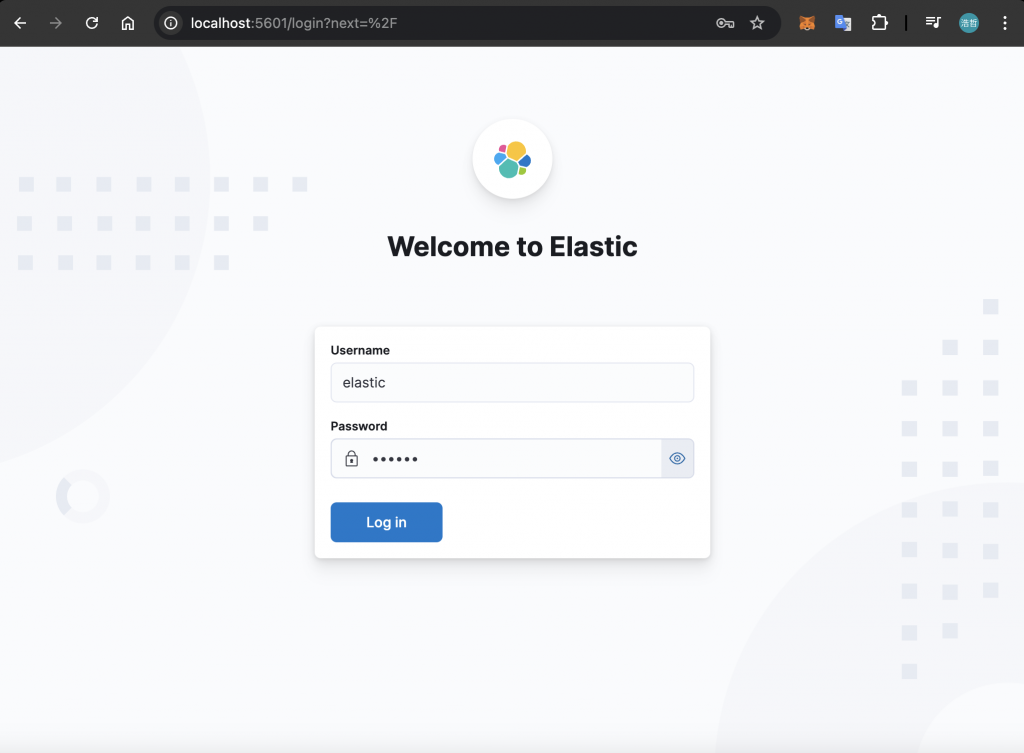
Kibana 完成設定後,就會跳轉至登入畫面,這邊可以使用預設帳戶 elastic 進行登入,密碼為前面透過環境變數 ELASTIC_PASSWORD 所指定的字串:
登入成功會看到 Kibana 首頁:
在完成 ELK Stack 的配置後,接下來將示範如何將 NestJS 應用程式的 Log 輸入到 ELK Stack 中。
製作一個簡易的 NestJS 應用程式並包裝進 Docker Image 進行測試,根據 DAY16 的內容設定好 pino Logger,然後在專案目錄下新增 Dockerfile:
FROM node:20-alpine3.19
WORKDIR /app
COPY . .
RUN npm install
RUN npm run build
ENV NODE_ENV="production"
CMD ["npm", "run", "start"]
注意:記得設定
.dockerignore來避免node_modules等肥大的資料夾被納入 Context 中。
接著,透過下方指令來打包 Docker Image:
$ docker build -t <IMAGE_NAME>
最後,透過下方指令啟動 Docker Container,將 log-driver 指定為 syslog,讓 Logstash 可以接收到來自這個 Container 的相關 Log 資料:
$ docker run --log-driver syslog --log-opt syslog-address=tcp:localhost:5000 --log-opt syslog-facility=daemon -p 3000:3000 <CONTAINER_NAME>
啟動完畢後,透過 Postman 存取 http://localhost:3000,然後回到 Kibana 的 Discover 頁籤,從這邊來驗證剛剛產生的 Log 是否有正確寫入 Elasticsearch 中。第一次進入會需要建立 Data View:
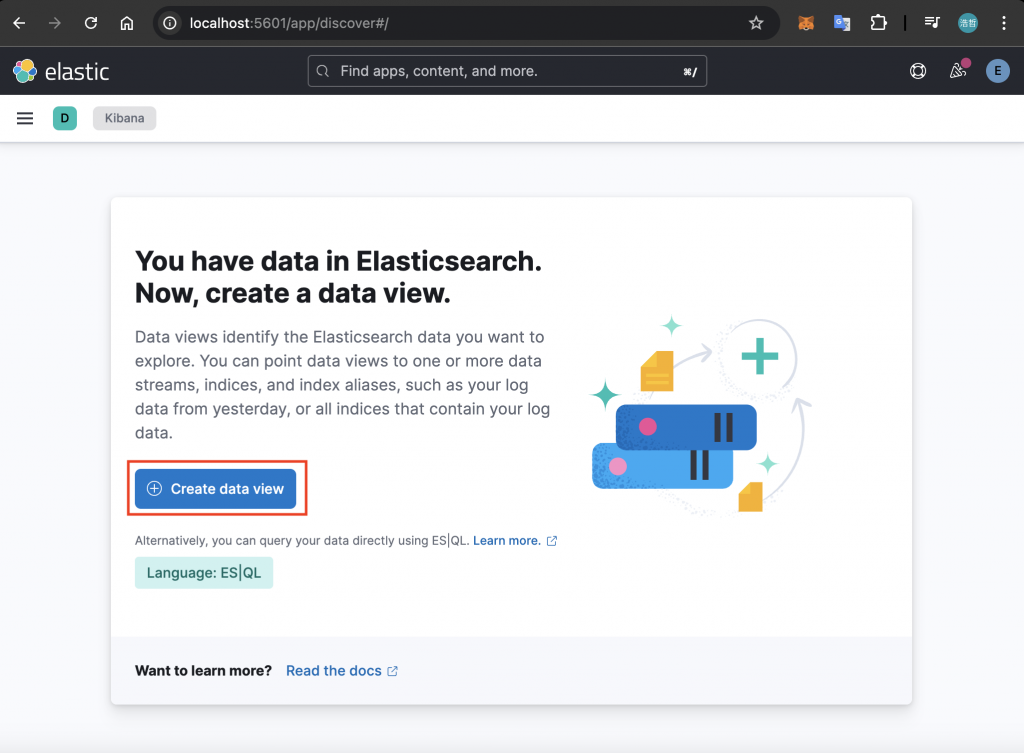
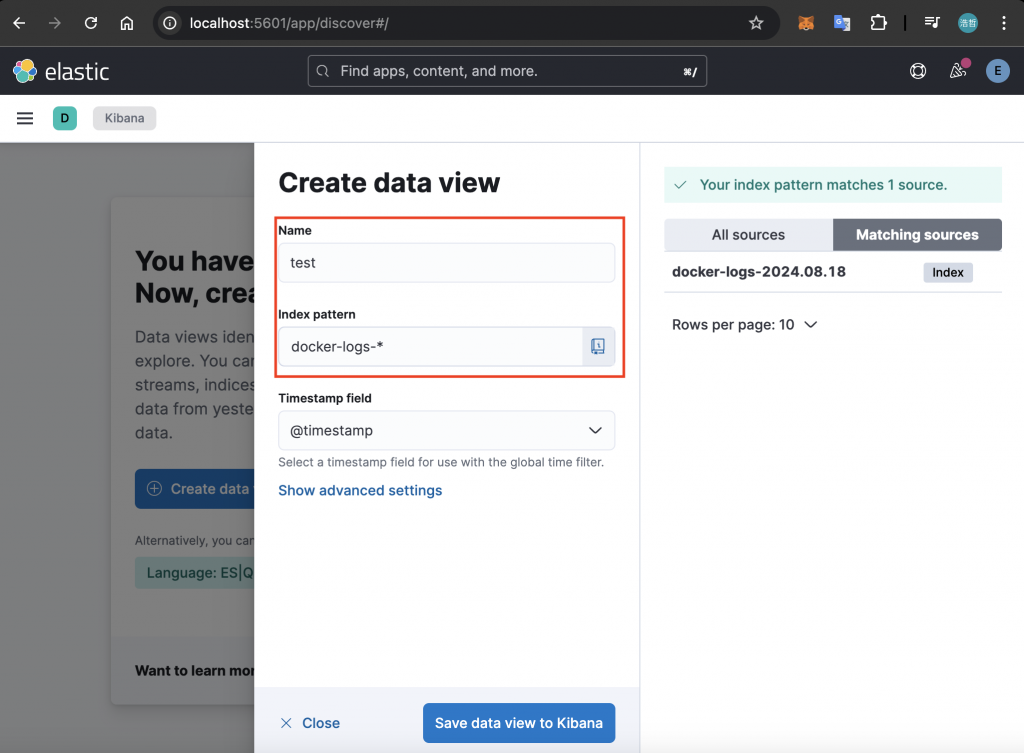
點擊「Create data view」之後,可以替該 Data View 命名,並透過指定Index Pattern 來決定資料會從哪些符合條件的 Index 進行搜尋。以下方圖片為例,將 Data View 命名為「test」,並設置 Index Pattern 為「docker-logs-*」:
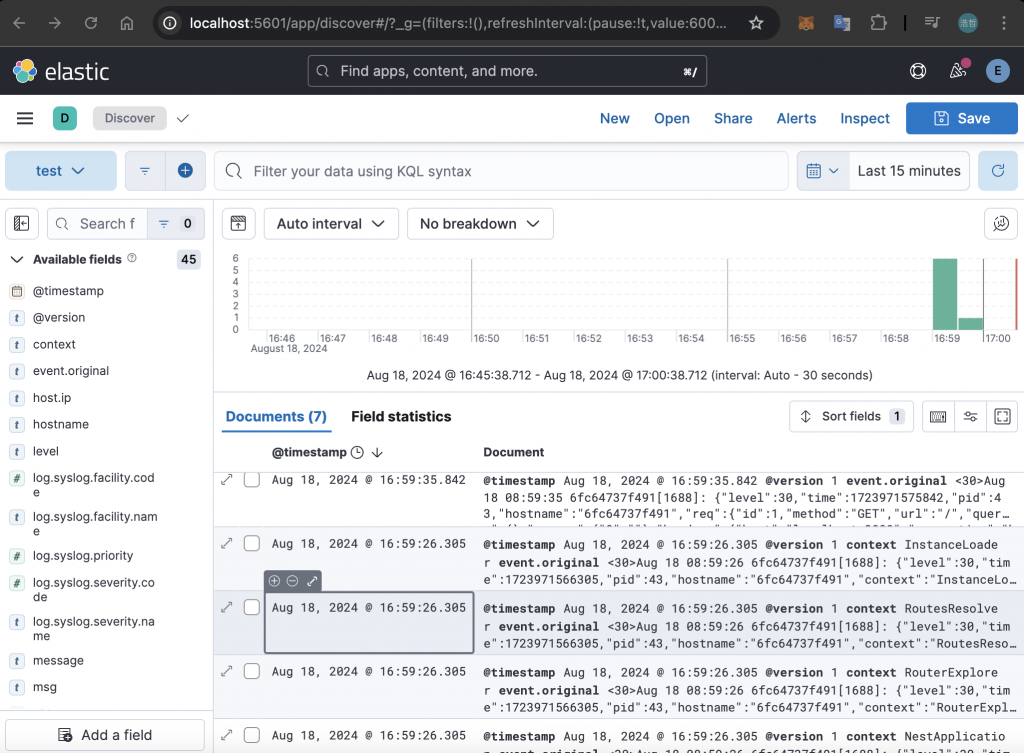
建立完之後,就會進入到 Discover 的畫面,預設是取得最近 15 分鐘的資料:
可以透過左邊的欄位表來調整表格呈現的欄位,以下方圖片來說,選擇 @timestamp、pid、level 與 message 顯示於表格中:
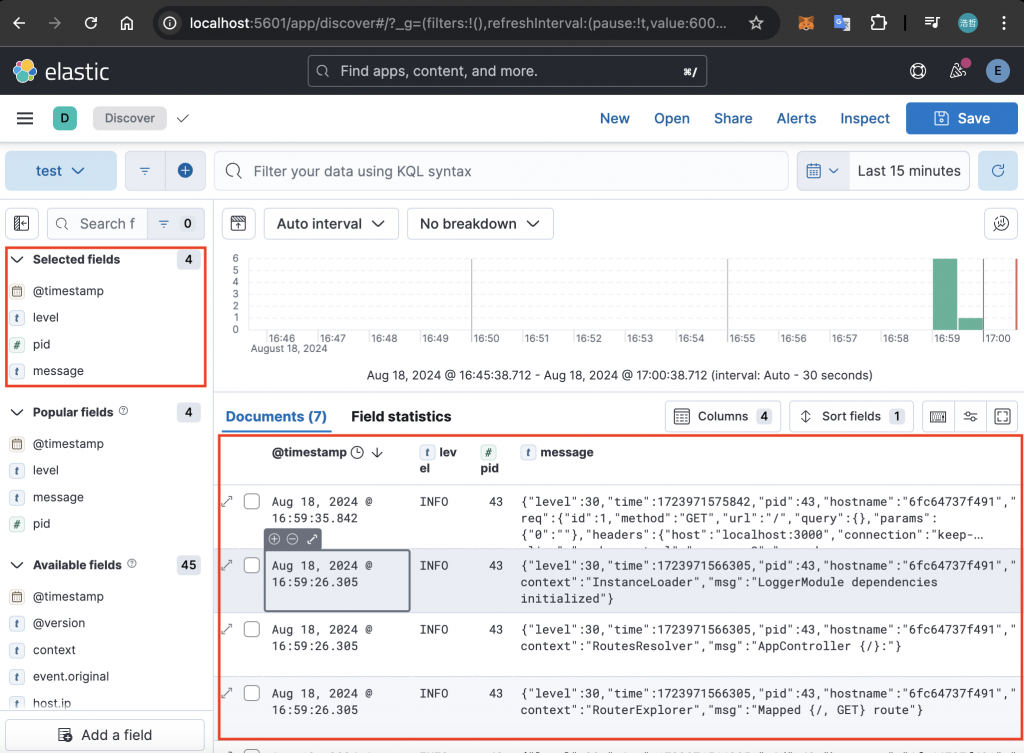
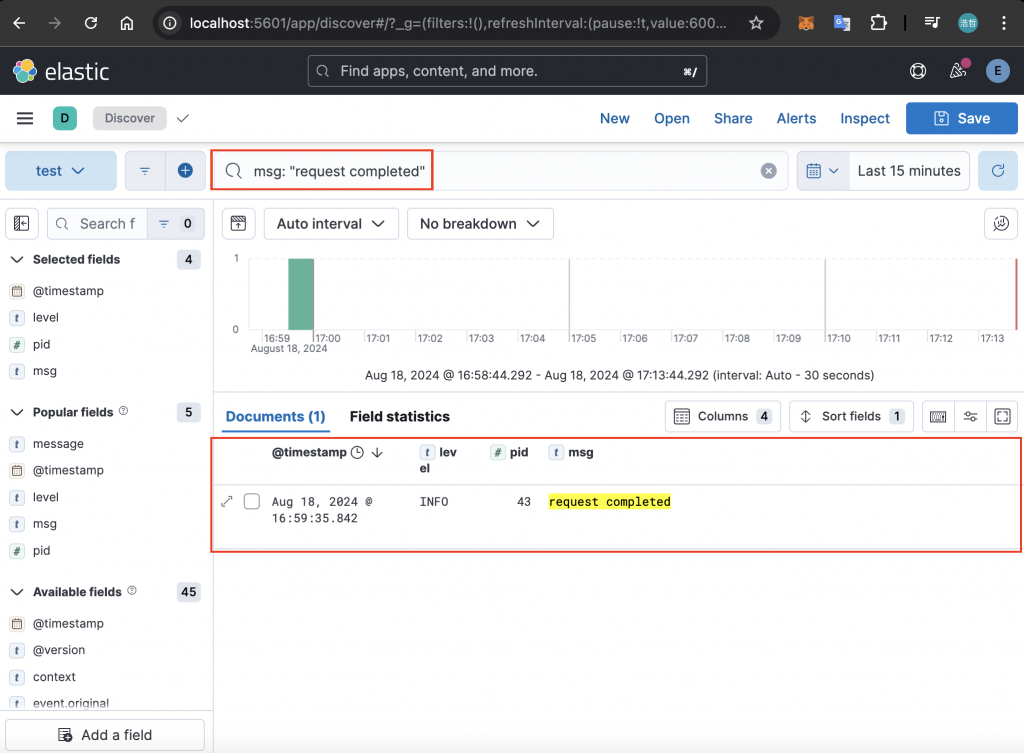
如果要搜尋特定欄位的資料,可以透過上方的搜尋框輸入 KQL 進行查詢。以下方圖片來說,搜尋 msg 欄位為 request completed 的資料,就會找到剛才存取 http://localhost:3000 留下的 Log:
在本篇文章中,我們探討了 ELK Stack 在 Log 管理中的應用,並逐步解說 Elasticsearch、Logstash 和 Kibana 三個核心元件的功能與特性。隨著服務規模的擴展,傳統的 Log 管理方式已不再適用,因此使用 ELK Stack 來進行集中化管理成為了最佳解決方案。
首先,介紹了 Elasticsearch 作為 ELK Stack 的核心,透過其分散式搜索和分析能力,能夠快速檢索和處理大量 Log 資料。接著,Logstash 作為資料處理管道,負責從多種來源收集並過濾資料,確保資料的高效傳輸和轉換。最後,介紹了 Kibana 這套視覺化工具,可以將複雜的 Log 資料轉化為易於理解的圖表和儀表板,讓使用者能夠更直觀地分析和監控系統。
本篇文章雖然沒有深入探討 ELK Stack 的進階應用,但也足以讓不熟悉的人認識這套技術,讓管理 Log 變得更有效率。


 iThome鐵人賽
iThome鐵人賽
{kind=link}